
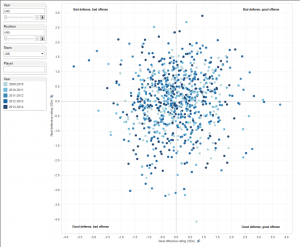
Click for a full-sized, interactive version
It’s not a mystery that I’ve been crusading to find a better measure for individual performance. But no matter what I seem to do, I run up against annoying obstacles. Chief among these annoyances is that individual performance is inextricably tied up in team performance. For example, I could suck on defense but if my center blocks the shot of the guy that zips by me then my defensive statistics look pretty good. Also annoying is that individual performance is biased towards certain positions. Any reliable measures have to at least take these two factors into consideration.
Up until now, I’ve been lazily trying to account for these biases by subtracting out averages one at a time. But I finally decided to roll up my sleeves and really get to work on it. Roughly four days of number crunching later, I’ve produced results that I’m quite proud of and, more importantly, confident in. Using five years of data encompassing over 2,500 players (sucks to your sample size), I was able to statistically control for the effect of team performance, position bias, and opponent performance on individual player ratings, leaving (hopefully) just the players’ individual performances. The link above provides a chart and two tables that shows all of the findings.
Let’s talk about the weather
To actually do what I just said, I had to use a method that you’ve probably heard of in hushed whispers. It’s called a linear regression. I’ll spare you the grad school pain and just provide a simple example that shows what a linear regression does, and how it can be used.
Let’s say I want to statistically predict the temperature of any place on Earth. You and I crack open a few beers and start identifying factors that probably affect temperature (because cracking open beers is what we do after deciding to do statistical work). We decide that the biggest factors that would influence the temperature of a place are latitude, time of year, and time of day. Then we go to a magical database that only exists in fairy tales and retrieve a bunch of data about the temperature of all places, at all latitudes, at all times of year, and all times of day. We then feed all of this information into a computer. With enough information, the computer can begin predicting temperatures around the world. So if we want to know what the temperature in Helsinki is right now, we tell the computer the latitude of Helsinki, the time of year, and the time of day. The computer then spits out a predicted temperature based upon all the information we’ve fed it from before.
But all of a sudden your crazy aunt calls us, and she happens to be the president of Finland. She says that she ordered every city in Finland to become warmer by making everyone to rub their hands together 24/7, and wants to know which cities have succeeded the most. She knows she can’t just take a look at the raw temperatures because some cities are supposed to be colder than others, because they’re farther north or something. So what to do? First, we crack open more beers. Then we tell the computer to perform one extra step. We get the actual current temperature of all cities in Finland and give it to the computer. The computer does the same thing it did before–predict the temperatures for the cities based upon the information we gave it from before. But now it subtracts the actual temperatures of the cities from the predicted temperatures. We can then identify which cities have temperatures wildly different from what we would expect given historical data.
NOTE: This isn’t the technical definition of a linear regression and actually encompasses a spin off concept called a residual. But you don’t care about that. You just care that this is an example of what I did to produce this post.
Basketball
OK, enough with the weather. What I did was grab data from all NBA players from the last five years. The specific factors I was interested in was players’ teams, players’ positions, players’ individual offensive and defensive ratings, players’ teams offensive and defensive ratings, and players’ opponents offensive and defensive ratings (basketball reference thankfully did this last step for me, combining team and opponent ratings into one stat). I then fed all of this information into my computer, weighted according to the number of minutes each player played, and asked it to predict what each player’s individual ratings should be given how good their teams’ ratings were, how good their opponents’ ratings were, and their positions.
The for all players who played at least 50 games (35 games for this season) and at least 22 mpg, I subtracted their actual individual ratings from their predicted ratings, leaving us with what I call the players’ real ratings. A real rating is basically what’s left of a player’s offensive or defensive rating after we take out the effects of his position, team, and opponents. Finally, I standardized those ratings into standard deviations.
Some notes
When interpreting the chart and tables, don’t think of it as player X is better than player Y. Think of it as player X is doing better than would be predicted relative to player Y.
I’m also not going to talk about limitations because the last thing I want to do after all this work is identify everything that could be wrong with it.
Observations
Still with me? You better be, because I spent a lot of time on this. There’s an enormous amount that can be pointed out, and I’ll let everyone else do most of it. Here are just a couple of teasers.
- Talk of Dwight Howard’s decline are true. From 2009-2012, his real defensive rating was over three standard deviations. If this were a standardized test, that would be 99th percentile, and he did it for three straight years. He was first in the league in two of those years, and second in the other one. Last year though, his real rating dipped to 1.8 SDs, and this year it’s 1.3 SDs.
- Sustained success should be rewarded. Check out someone like Chris Paul. Both his offense and defense are consistently amazing. Also Josh Smith’s defense, which doesn’t receive too much publicity.
- Trends are also worth noting. We know that Howard is trending downward, but look at Steph Curry’s offense… and his defense. Anthony Davis is setting up to be some kind of monster. Tony Parker’s defense might be the least-but-should-be-most criticized element of anyone’s game. Boogie Cousins’s defense should maybe receive more attention.
- Tyson Chandler’s offensive ratings are insane, not just because they’re high but because they’re consistent and he’s not exactly an offensive juggernaut himself. I guess that goes to show you don’t need to be a prolific scorer to help your team put points on the board.
- In true moneyball/analytics fashion, a few diamonds in the rough are popping up. Most notable is Martell Webster, who is actually the highest rating offensive player this year and second highest last year. Remember, this doesn’t mean he’s the best offensive player. It means he’s doing the best given his circumstances relative to everyone else and their circumstances. This could be the result of dumb luck (unlikely since he did it last year too), talent, or that he might fit his role perfectly. I don’t know enough about the Wizards to speculate past that.
Something geeky and statistical worth mentioning
When doing linear regressions, there’s a statistic called the R-squared. Technically stated, R-squared represents the amount of variance in a dependent variable (individual ratings in our case) that is explained by the independent variables in the model (position, team performance in our case). In more layman’s terms, it means how complete a model is, or how much of something can be accounted for by other somethings.
I mention this because, for defense, position, team performance, and opponent performance accounted for a whopping 80% of individual performance. For offense, it was only 18%. That 80% of humongous. It means a couple of things. First, that factors outside of an individual player’s control are largely responsible for deciding an individual’s defensive rating. Second, if there’s something else going on that the model has not considered (which there always is), that something is not very important.
The opposite is true for offense. Position, team performance, and opponent performance are not responsible for very much of a player’s individual offensive rating. Either his own performance is very responsible for his own rating, or there’s something else going on that the model has not considered (which there always is) that’s really impacting players’ offensive ratings. The smaller R-squared for offense might also help explain why the offensive ratings are a little more unexpected than the defensive ratings–the model is just less complete.
A final comment
This is more of a pet peeve of mine. The whole point of data is to help make conclusions. It is not to confirm an already existing conclusions. If you think that player X is the best player ever, and a piece of data analysis does not rank player X as the best player ever, the wrong reaction to have is to claim that the data analysis is wrong. That’s not how this exercise works. You can and should find faults in the data that was used, or the methods, but a pre-formed opinion should never be used to criticize the results.
View this discussion from the forum.


